When your agents fail, can you tell which one did it?
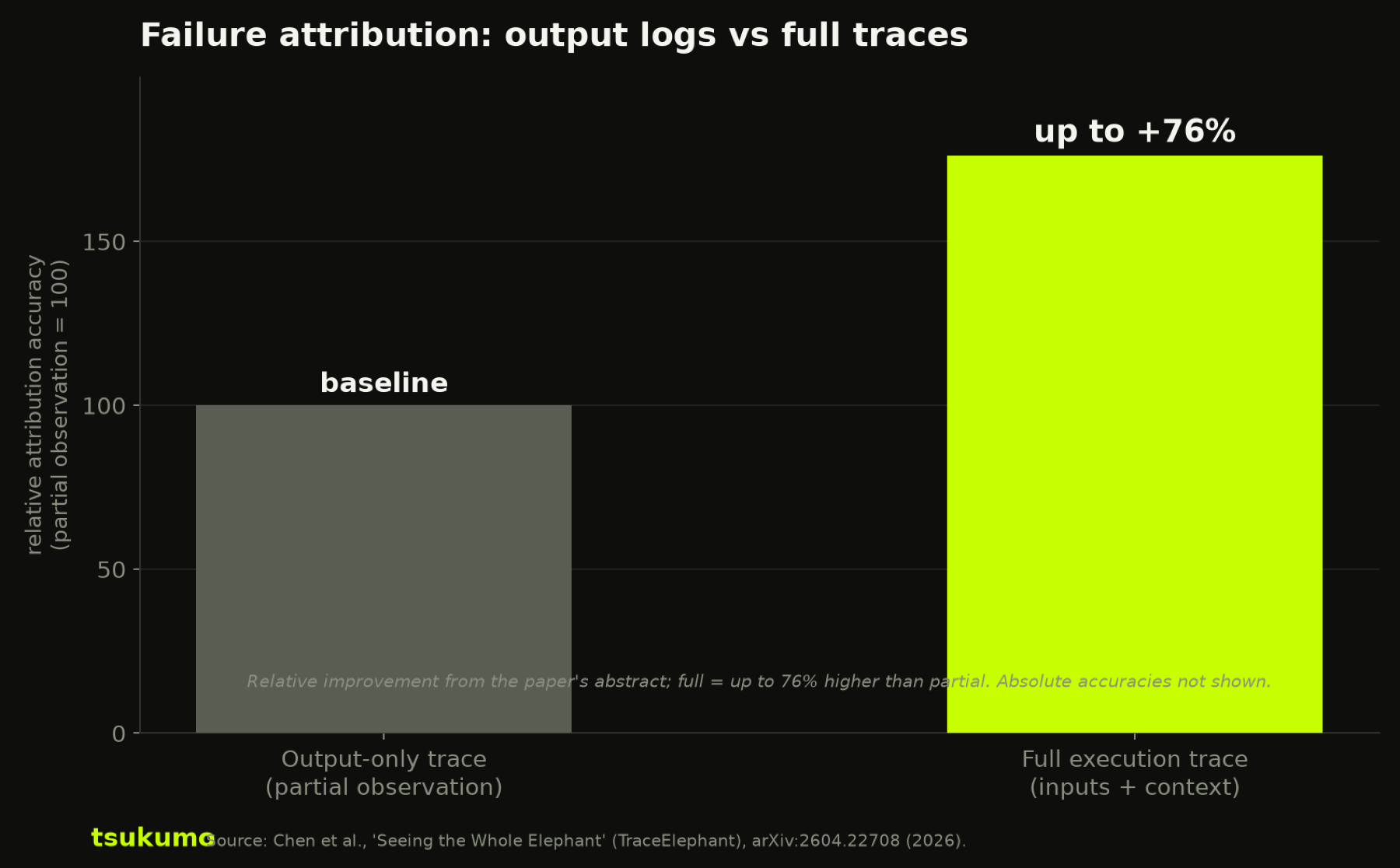
A multi-agent system fails and you have to find the one step that caused it. If your traces only logged what each agent said, not what it saw, you mostly can't. A 2026 benchmark found full traces improve failure attribution by up to 76% over output-only logs.
tsukumo
Short version: A multi-agent system produces a wrong result, and now you have to find the one agent and the one step that caused it. If your observability only logged what each agent said, you are mostly stuck, because the cause usually lives in what an agent saw, not what it wrote. A 2026 benchmark put a number on the gap: full execution traces, the ones that capture inputs and context and not just outputs, improved failure attribution accuracy by up to 76% over output-only traces. The lesson is uncomfortable and concrete. The trace you kept to save space is the trace that can't tell you what went wrong.
If you have run agents in any kind of fleet, you know this moment. Something downstream is broken, the logs show a tidy sequence of agents each reporting they did their part, and nowhere in there is the actual mistake. Everyone said the right thing. The system still failed.
Because the failure lives in the handoffs, and the handoffs are the part you usually didn't record. Multi-agent systems reason in natural language, produce nondeterministic outputs, and pass context from one agent to the next in ways that compound. A wrong final answer can trace back to a subtly bad input that one agent handed another several steps earlier. Each individual agent looks like it behaved. The defect is in what it was given, not in what it said.
That is what makes attribution hard. It is not enough to know the system failed. You need to find the responsible agent and the decisive step, and in a natural-language system with many interactions, that needle is in a very large haystack.
What is failure attribution, and why does it need full traces?#
Failure attribution is identifying the responsible agent and the decisive step of a failure. It is the real question behind agent debugging: not that something broke, but exactly where and why. The 2026 paper TraceElephant makes the case that you cannot study attribution honestly on the traces most systems keep, because those traces capture only agent outputs and omit the inputs and context a developer actually uses to debug.
So the benchmark was built the other way around, on full execution traces with reproducible environments, matching what a developer sees at the moment of diagnosis. And when attribution techniques were evaluated across configurations, the level of observability mattered more than anything else on the page.
up to 76%
higher failure-attribution accuracy with full execution traces than with an output-only, partial-observation counterpart
measured on TraceElephant, a 2026 benchmark of failure attribution in LLM multi-agent systems built on full traces and reproducible environments
Source: Chen et al., TraceElephant, arXiv:2604.22708 (2026)
How much does partial observability actually cost you?#
Up to 76% of your attribution accuracy, by this benchmark. That is the gap between a trace that logged only what each agent said and one that also captured what each agent saw. Output-only logging is the default in a lot of agent stacks, because outputs are cheap to store and look complete in a dashboard. The benchmark's finding is that this default quietly removes the information that makes a failure explainable. Missing inputs obscure many of the causes.
What an output-only trace keeps, and what it drops
What you debug with
Output-only trace
Full execution trace
Each agent's final output
Kept
Kept
The inputs and context it saw
Dropped
Kept
Why a handoff was wrong
Invisible
Reconstructable
Reproduce the exact run
No
Yes (with the environment)
Relative attribution accuracy. Full execution traces score up to 76% higher than output-only traces (shown relative to the partial-observation baseline). Source, Chen et al., TraceElephant, arXiv:2604.22708.
The inputs and context each agent saw, the action it took, and enough of the environment to replay the run, not an output log. The benchmark's argument is that attribution should be studied under full execution observability, the complete trace rather than a summary of outputs, because that is what a developer has in front of them when they debug for real.
Concretely, an attributable trace records, per step: the input the agent received, the context and tool results it had access to, the action it took, and the result, with enough environment captured to reproduce the run. That is a heavier trace than an output log. It is also the difference between a failure you can explain and one you can only re-roll and hope.
“Full execution traces improve failure-attribution accuracy by up to 76% over a partial-observation
counterpart that captures only outputs. TraceElephant is built on full traces and reproducible
environments, on the argument that attribution should be evaluated under the full observability a
developer actually has when debugging.”
How do you build observability you can actually debug from?#
Capture for attribution, not for a dashboard. The two goals pull in different directions: a dashboard wants tidy summaries, attribution wants the raw inputs that summaries throw away. Build for the second.
Trace inputs, not just outputs. Record what each agent received and the context it had, per step, alongside what it returned. This is the single change the benchmark says moves attribution most.
Keep the run reproducible. Capture enough of the environment to replay a failure, so you can re-execute the decisive step instead of guessing at it.
Make the trace step-addressable. Structure it so you can point at the responsible agent and step, which is the whole output of attribution, rather than scrolling a flat log.
Treat observability as part of reliability, not a bolt-on. A failure you can't attribute is a failure you can't fix, so this sits underneath every other reliability practice.
This is the discipline we build with teams whose agents fail in ways nobody can explain, and it is part of the operating model that makes agents reliable in production: you cannot fix what you cannot attribute, and you cannot attribute from a trace that kept only outputs. It pairs with agent observability as the deeper, debugging-grade version of the same idea.
If your agents fail and the honest answer to "which step caused it" is a shrug, you do not have a debugging problem yet. You have an observability gap that guarantees one. That's the work we do with teams.
We find where your agent traces drop the inputs that make a failure explainable, and build the attribution-grade observability that turns a mystery failure into a fixable one, on your stack.
Because failures hide in the interactions, not one place. Multi-agent systems reason in natural language, produce nondeterministic outputs, and pass context between agents. A wrong final answer can trace back to a bad input one agent handed another several steps earlier, which is invisible if you only logged the outputs.
What is failure attribution in agent systems?
Failure attribution is identifying the responsible agent and the decisive step that caused a failure. It is the core question of agent debugging: not just that the system failed, but exactly where and why. A 2026 benchmark, TraceElephant, was built to measure how well attribution techniques actually do this.
Do you need full traces to debug agent failures?
Largely yes. The 2026 benchmark found that full execution traces, capturing inputs and context rather than only agent outputs, improved attribution accuracy by up to 76% over partial-observation traces. Missing inputs obscure many failure causes, so output-only logging leaves most failures hard to attribute.
What should an agent trace capture?
The inputs and context each agent actually saw, not just what it produced, plus enough of the environment to reproduce the run. The benchmark argues attribution should be studied under full execution observability, matching what a developer needs at the moment of debugging: the complete trace, not a summary of outputs.