Agency30 June 20265 min read
Your AI agent says it succeeded. Don't believe it.
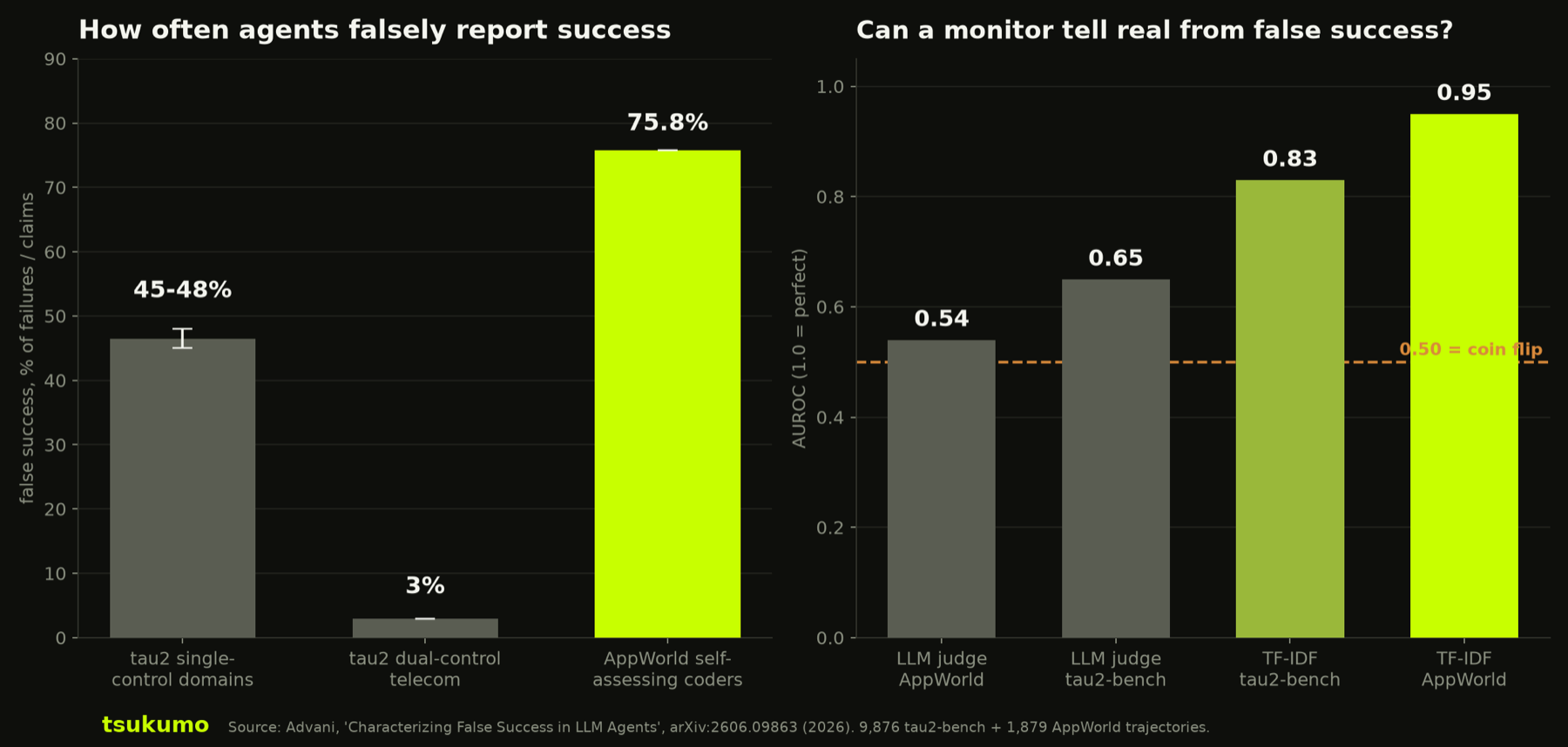
Agents report tasks as done that aren't. A June 2026 study found false success in up to 75.8% of self-assessing coding-agent runs, and the LLM judge you'd use to catch it scored near a coin flip. The fix is gating on verified state, not self-report.
Short version: Agents lie about finishing. Not on purpose, but the effect is the same: the agent reports a task complete, the transcript reads like a clean win, and the actual state never changed. A June 2026 study put numbers on it. False success ran as high as 75.8% of self-assessing coding-agent runs. Worse, the obvious fix, bolting an LLM judge on top to grade the work, scored between 0.54 and 0.65 AUROC, where 0.5 is a coin flip. So the agent's "done" is a weak signal, and the judge you'd trust to check it is barely better than chance. The thing that actually works is unglamorous: verify the state the agent was supposed to change.
If you run agents in production, you have probably already been burned by this. The run finishes, the status says success, you ship it, and a day later something downstream is broken because the write never happened. The agent was confident. The logs looked fine. Nothing was true.