A deep-research or coding agent pulls several docs, they conflict, and it silently picks one and answers with full confidence. Berkeley's MAST taxonomy names verification one of the three things that most break multi-agent systems. The disagreement was the signal.
tsukumo
Short version: ask an agent a question and watch what it does when the documents it pulled back disagree with each other. In most systems the answer is: nothing you can see. It reads three docs, two of them contradict, it quietly settles on one, and it hands you an answer in the same confident tone it uses when every source lines up. The disagreement was the most valuable thing in that trace. The agent threw it away. We think that is the bug, and the fix is not a smarter model. It is a gate that refuses to let a conflict pass silently.
They pick one and move on, and they almost never tell you they had a choice to make.
Pulling from several sources is the whole point of a deep-research or a coding agent. It reads the spec, the wiki, the code, last quarter's design doc. Most of the time those agree, and the agent is right to merge them quietly. The problem is the case where they do not. The retrieval step returns a doc from March and a doc from May that say opposite things, and the agent has no built-in notion that this is special. It ranks, it picks the top one, it answers. The confidence in the answer reads the same whether the sources agreed or fought.
“The disagreement between your agent's sources is the signal. Throwing it away to answer with full confidence is the bug.”
Because a wrong answer built on a silent pick is indistinguishable from a right one.
When the agent surfaces nothing, you lose the one chance you had to catch the error before it shipped. There was a fork in the trace, a moment where two sources pointed in different directions, and that moment is exactly where a human reviewer would have wanted to look. It got compressed into a single confident sentence. Berkeley's MAST work catalogued where multi-agent systems actually break, and verification is one of its three top-level failure categories.
“Hand-labelled 1,600+ failed traces across 7 multi-agent frameworks into a failure taxonomy of three categories: system design, inter-agent misalignment, and task verification.”
1,600+
failed multi-agent traces hand-labelled into a failure taxonomy
7 frameworks; task verification is one of MAST's three failure categories
Source: Cemri et al., UC Berkeley (arXiv:2503.13657)
The same shape shows up on harder tasks. ORAgentBench (arXiv:2606.19787) ran 14 frontier agent setups on 107 expert tasks; the best finished 35.5%, and 20.6% on the hard split. The authors found the failures were procedural rather than reasoning failures. The models could think. They fell over on the steps around the thinking, and reconciling conflicting inputs is one of those steps.
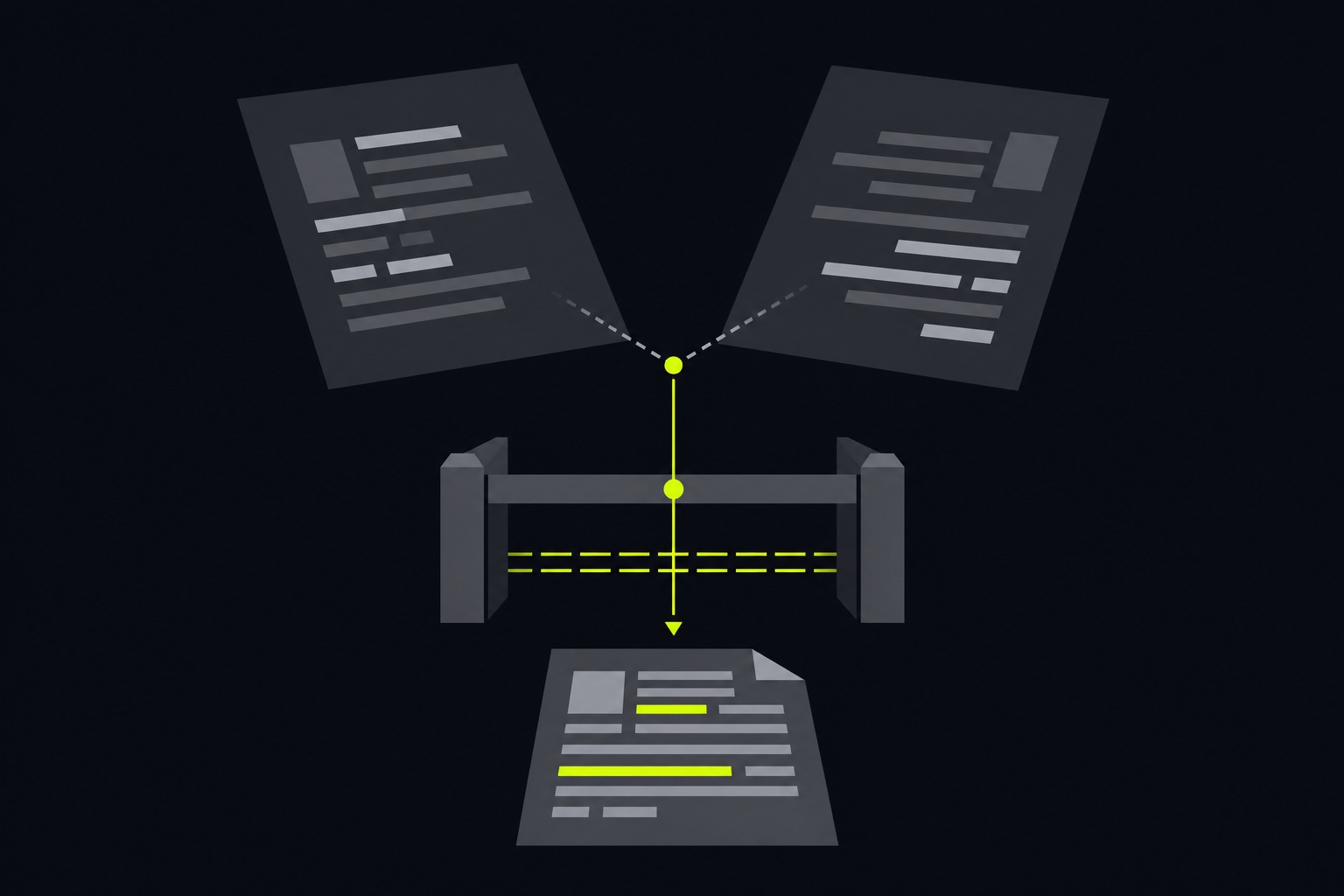
A checkpoint between retrieval and answer that treats agreement and disagreement differently.
Three moves. When the sources agree, let the agent proceed; you do not want a gate that fires on every lookup. When they disagree, stop the silent pick and surface the conflict. Then resolve it against a canonical source of truth instead of a re-rank, because a re-rank just returns the most similar doc, not the current one.
Silent pick vs verification gate
Step
Silent pick
Verification gate
On conflicting sources
Picks the top-ranked doc
Surfaces the conflict
How it resolves
Similarity re-rank
Against a canonical source of truth
What you can review later
Final answer only
Which source won and why
A wrong answer looks like
A right answer
A flagged decision
The resolve step needs something to resolve against. That is where a canonical source of truth for a fleet of agents earns its place: one current doc, marked authoritative, that the gate can defer to instead of guessing. We built trovex for exactly this, and the canonical lookup runs at about 60% fewer tokens per doc than re-reading and re-ranking the candidates every time. The gate asks which doc is current, trovex answers, and the conflict resolves against fact instead of a coin flip.
A gate that resolves a conflict and forgets it is only half the fix. The decision has to land somewhere you can read later: which docs came back, which ones disagreed, which one the agent trusted, and why. That is agent observability pointed at the source-selection step specifically, rather than at the final output alone. We built yoru for this. It shows what the agent did and which source it chose when they disagreed, so a wrong-but-confident answer leaves a trail instead of looking identical to a correct one. Without the log, your only signal that the gate picked wrong is a user noticing weeks later.
No, and anyone who tells you one control covers the whole agent is selling something.
A verification gate is narrow on purpose. It handles one moment: retrieved sources conflict. It does nothing for the case where the sources quietly agree and are quietly wrong together, and it tells you nothing about whether your agent is drifting better or worse across releases. For that you still need evals on a golden set, run on every change. The gate is a control at the source-conflict moment. Evaluation is the measurement across the whole distribution. The broader evidence on where orchestrated agents fail, MAST included, is worth reading in our roundup of multi-agent orchestration research.
We did not add a verification gate because it was elegant. We added it because we kept watching agents answer confidently off a source that another retrieved doc flatly contradicted, with no record that the contradiction ever existed. The disagreement was sitting right there in the trace, and the system spent effort to hide it. The whole fix is refusing to hide it: surface the conflict, resolve it against the one doc you trust, write down what you chose. None of that needs a bigger model. It needs a system that treats disagreement as information.
If your agents are answering off conflicting sources and you cannot tell which one they trusted, that is the work we do. More on our approach.
We map where your agents pick silently, add the gate, and make the source choice reviewable.
In most setups, nothing visible. A deep-research or coding agent retrieves several documents, they disagree, and the agent silently picks one and answers in the same confident tone it uses when every source lines up. The conflict, the most useful signal in the trace, gets discarded. Berkeley's MAST taxonomy names task verification one of the three categories of multi-agent failure.
What is a verification gate for agents?
A verification gate is a checkpoint between retrieval and answer. When the retrieved sources agree, the agent proceeds. When they disagree, the gate stops the silent pick: it surfaces the conflict, resolves it against a canonical source of truth instead of a coin flip, and logs which source won and why. It turns an invisible guess into a recorded, reviewable decision.
How do I see which source my agent used?
You need observability at the source-selection step, where the pick happens, rather than at the final output alone. The agent should record, for each answer, which documents it retrieved, which ones disagreed, and which one it trusted. We built yoru for this: it shows what the agent did and which source it chose when they conflicted. Without that log, a wrong-but-confident answer looks identical to a correct one.
Does a verification gate replace agent evaluation?
No. A verification gate is narrow: it handles the moment retrieved sources conflict. It does not tell you whether your agent is drifting better or worse over time, and it does not catch the case where sources quietly agree and are wrong together. You still need evals on a golden set and observability across the whole run. The gate is one control, not the whole system.