RAG in production over regulations and client documents
Production RAG over regulations isn't embed-and-retrieve. It's a layered pipeline (hybrid search, reranking, hierarchical summaries, graph context), and the failure that bites hardest is a silent embedding-dimension mismatch that returns confident garbage.
tsukumo
The short answer
Production RAG over regulations and client documents is not embed-and-retrieve. It is a layered pipeline: hybrid search (dense vectors plus keyword BM25), a cross-encoder reranking pass, hierarchical summaries so retrieval can work at the right altitude, and graph context to connect related rules. And the failure that hurts most is silent: an embedding-dimension mismatch that returns plausible, confident garbage with no error. Naive RAG demos beautifully and fails quietly on real corpora.
Short version: retrieval-augmented generation looks trivial in a demo and gets hard the moment the corpus is real. Over a fiduciary's regulations, internal procedures, and client documents, naive embed-and-retrieve returns passages that are semantically close and factually wrong. What holds in production is a layered pipeline: hybrid search, a reranking pass, hierarchical summaries, and graph context. And the failure that cost us the most was silent: an embedding-dimension mismatch that returned confident garbage without throwing a single error.
Because pure vector search optimizes for "sounds similar," and regulations punish that.
Regulatory and procedural text is dense, repetitive, and full of exact references: article numbers, codes, defined terms. Dense vector search blurs exactly those. Ask about a specific provision and a vector-only system happily returns a passage that is semantically adjacent and legally different, which in this domain is just wrong. The demo works because the questions are easy. The real corpus is where the gap shows.
Naive RAG vs. the pipeline that holds
Concern
Naive embed-and-retrieve
Production pipeline
Exact references (article numbers, codes)
Blurred by dense vectors
Caught by BM25 keyword search
Candidate ordering
Trusts the raw retrieval score
Cross-encoder reranks against the query
Broad questions
Stitches fragments together
Answered from a summary node
Related provisions
Isolated chunk
Connected via graph context
Wrong embedding space
Returns confident garbage, no error
Caught by a fixed relevance test
Prefer this built rather than figured out? That's the studio: we ship it on the same fleets we'd hand your team.
Each stage exists because the stage before it is not enough on its own.
Stage
What it adds
Hybrid search (dense + BM25)
Vectors for meaning, keyword search for exact terms and references
Cross-encoder reranking
Re-orders candidates by true relevance, beyond the raw retrieval score
Hierarchical summaries (RAPTOR)
Lets retrieval work at the right altitude: summary for broad, leaf for specific
Graph augmentation
Connects related rules and references so context isn't a disconnected chunk
Multiple collections
Keeps distinct corpora (regulation vs procedure vs client docs) cleanly separated
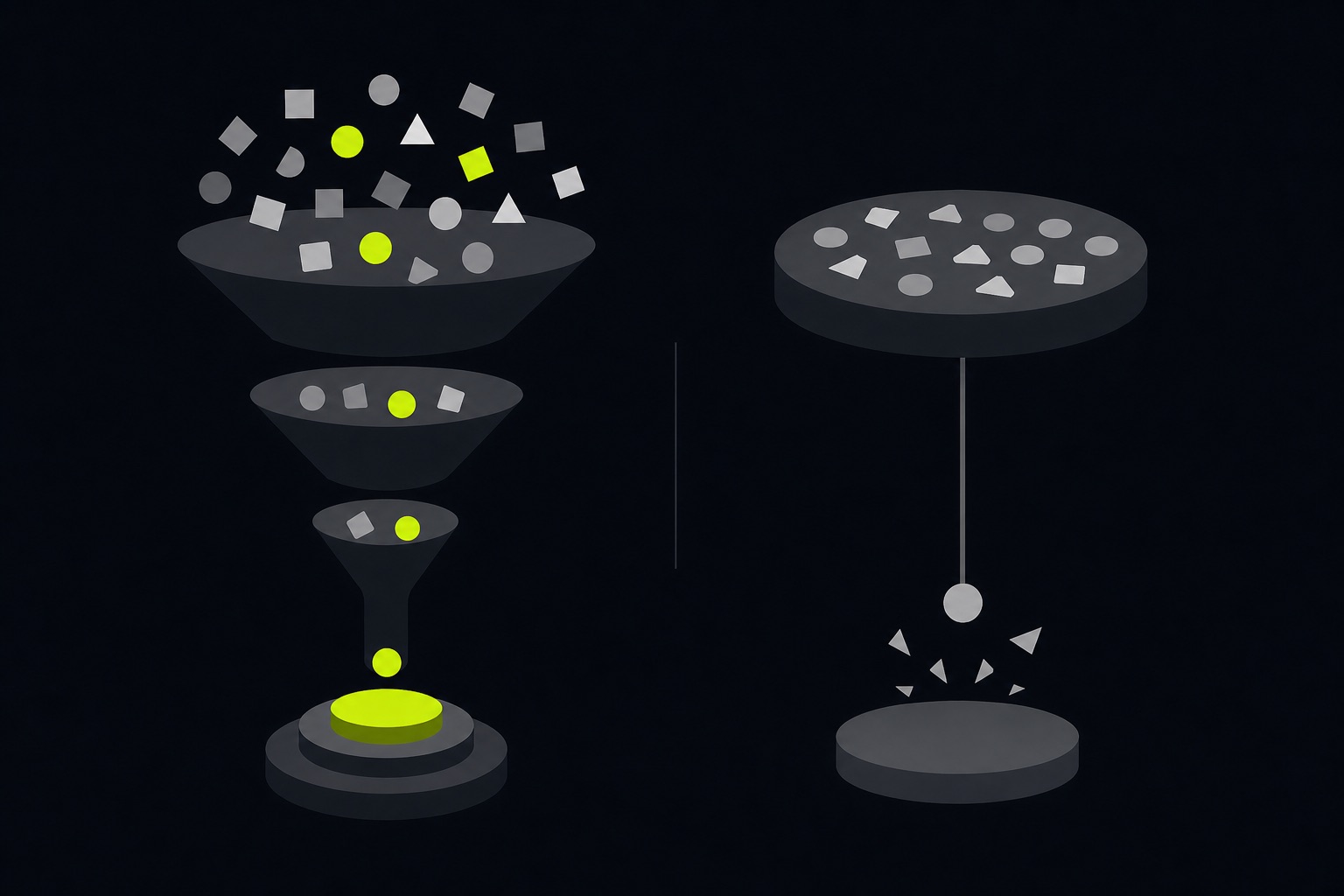
The shape to internalize: retrieval is not one query against one index. It is a funnel. Cast a wide net with hybrid search, narrow it with a reranker, and resolve altitude with hierarchy. Each stage is cheap insurance against a specific way the previous one is wrong.
Dense vectors catch the question whose wording differs from the source. BM25 keyword search catches the article number and the defined term the vectors smear. Run both, merge the candidates. On a regulatory corpus, dropping either one visibly degrades the answers.
First-pass retrieval gets you roughly the right neighborhood. A cross-encoder reranking pass then scores each candidate against the actual query and re-orders them, so the passage that truly answers the question rises to the top instead of merely being in the top fifty. For a generation step that only reads the top few, this ordering is most of the quality.
Hierarchical summaries let a broad question be answered from a summary node instead of a brittle stitch of fragments. Graph augmentation connects a rule to the rules it references, so the retrieved context is a connected neighborhood rather than an isolated chunk. Together they fix the two things flat retrieval cannot: working at the wrong level, and losing the links between related provisions.
The failure that bites: a silent embedding-dimension mismatch#
The worst RAG bug we hit threw no error at all.
The embeddings in the store had been produced with a different model configuration than the one used at query time, so the stored vectors and the query vectors lived in subtly different spaces. Nothing crashed. Similarity was still computed, just against the wrong geometry, so retrieval returned results that were plausible, confident, and wrong.
The lesson: pin the embedding model and dimensions as a hard contract between the index and the query path, and test retrieval quality against a fixed question set. An embedding space mismatch is invisible to error monitoring and obvious to a relevance check.
If you are building RAG over anything that matters, budget for the pipeline, not the prototype. Hybrid retrieval, a reranker, hierarchy for altitude, graph for connection, and a relevance test that would catch a silent embedding mismatch before your users do. The embedding call is the easy part. Making retrieval trustworthy on a real, messy, high-stakes corpus is the work.
We built this over a fiduciary's regulations and client documents, where a confidently wrong retrieval is worse than no answer. If your team needs RAG that holds up on real documents, that's the work we do.
We will pressure-test your retrieval against the questions your users actually ask, then tell you where it returns confident garbage.
Why isn't basic embed-and-retrieve enough for production RAG?
Because real corpora are large, technical, and full of near-duplicate language. Pure vector search misses exact terms and returns passages that are semantically close but wrong. Production RAG needs keyword search alongside vectors, a reranking pass to order candidates properly, and structure so it retrieves at the right level rather than the nearest chunk.
What is hybrid retrieval in RAG?
Hybrid retrieval combines dense vector search (semantic similarity) with sparse keyword search such as BM25 (exact-term matching). Vectors catch meaning when the wording differs; keywords catch precise terms, codes, and article numbers that vectors blur. Regulations are full of exact references, so you need both, then a reranker to merge and order the results.
What is the embedding-dimension mismatch failure?
It's when the embeddings in your store were produced by a different model or configuration than the one you query with, so the vectors don't line up. Often nothing errors. Similarity scores are still computed, just against the wrong space, so retrieval returns confident, plausible, wrong results. It's a classic silent failure and it can sit undetected for a long time.
What is RAPTOR / hierarchical retrieval?
It's building a tree of summaries over your documents so retrieval can work at multiple levels: a high-level summary node for broad questions, leaf chunks for specifics. For long regulations, this lets the system answer a general question from a summary instead of stitching together dozens of fragments, which improves both accuracy and cost.