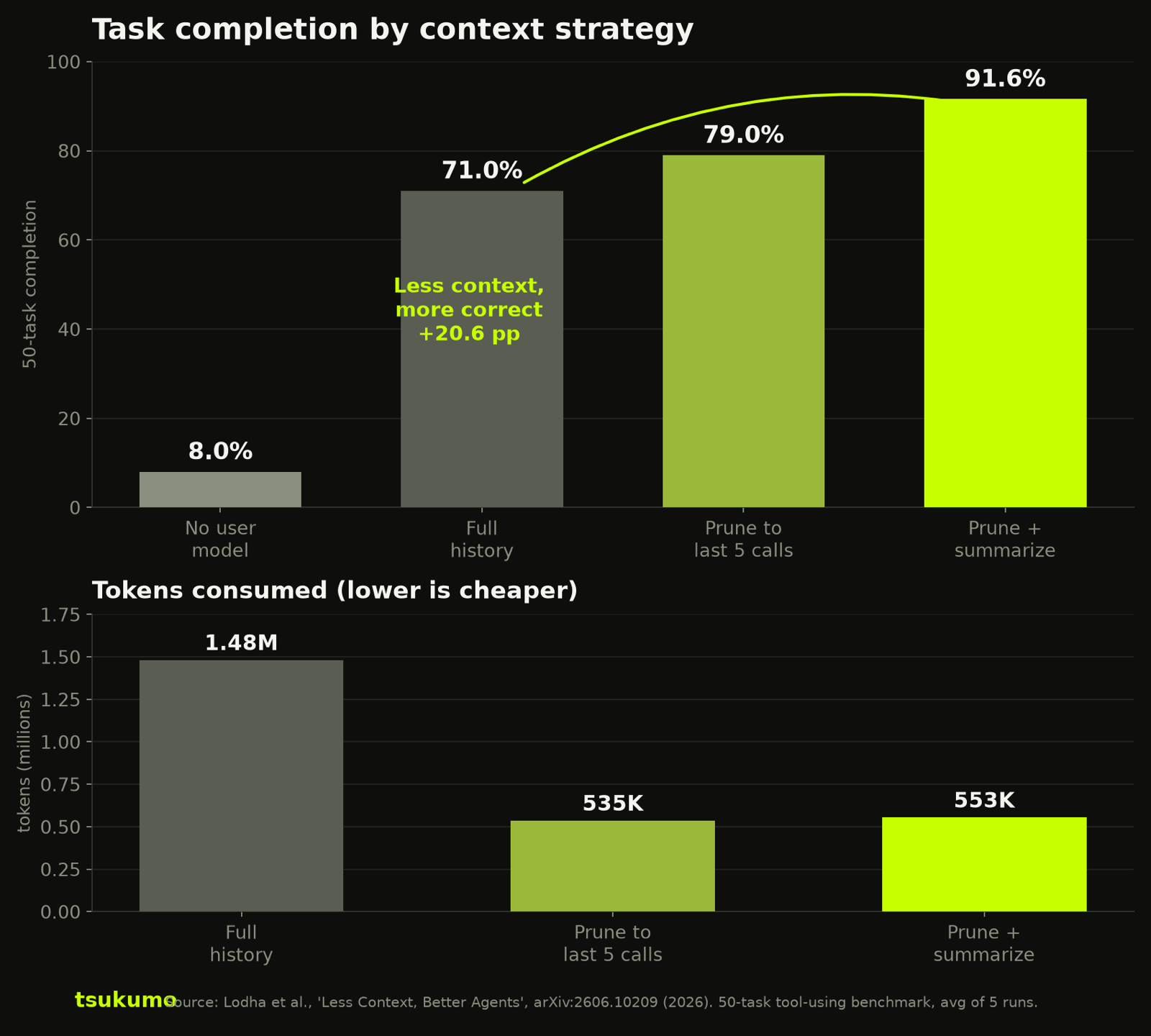
The reflex is to give an agent more context when it struggles. A June 2026 benchmark shows the opposite: keeping the full conversation history scored 71%, while pruning and summarizing hit 91.6%, on a third of the tokens. Selecting context beats hoarding it.
tsukumo
Short version: When an agent starts getting things wrong on a long task, the instinct is to give it more context. A June 2026 benchmark ran that instinct head-on. Keeping the full conversation history scored 71% on a 50-task workload. Pruning to the last five tool calls and summarizing the rest scored 91.6%, while spending a third of the tokens and under half the runtime. So more context did not buy accuracy. It bought a slower, more expensive agent that was also wrong more often. Choosing what to keep is the actual job.
You have probably felt this without naming it. An agent runs fine for the first few steps, then somewhere past the tenth tool call it starts repeating itself, re-reading output it already saw, or confidently acting on a number from twenty messages ago that no longer holds. The reflex is to widen the window and pour in more history so it "remembers everything." The new research says that reflex is backwards.
Does keeping full context improve an agent's accuracy?#
No. The paper Less Context, Better Agents (arXiv:2606.10209) built a 50-task benchmark around a hotel-expense workflow, with the agent driving real enterprise tooling over MCP, and ran four context strategies through it. Every result below is averaged across five independent runs.
Full conversation history, the "remember everything" default, finished 71.0% of the tasks. Pruning the context to just the last five tool-call and response pairs scored 79.0%. Adding automated summarization of the older context on top of that pruning reached 91.6%, at a 99.64% average amount itemized. Stripping the user model out entirely collapsed to 8.0%, which mostly tells you the task is real and not trivially solvable.
71% to 91.6%
task completion rises when full conversation history is replaced by pruning plus summarization
50-task tool-using benchmark, averaged across five runs; full history = 71.0%, prune to last 5 calls = 79.0%, prune + summarize = 91.6%
Source: Lodha et al., Less Context Better Agents, arXiv:2606.10209 (2026)
Read those two middle numbers again. The configuration that threw context away outscored the one that kept all of it, by more than twenty points. This is not a rounding wobble. It is the headline.
Task completion by context strategy
No user model8 %
Full history71 %
Prune to last 5 calls79 %
Prune + summarize91.6 %
Source: Lodha et al., arXiv:2606.10209 (2026), 50-task benchmark, avg of 5 runs
Because most of that context is stale by the time the model re-reads it, and the model has no reliable way to tell the live parts from the dead weight. Every extra turn of history is more tokens the agent reprocesses on the next step, more old tool output competing for attention with the thing that actually matters now, and more surface area for it to anchor on a value that has since changed. Long histories do not preserve signal. They dilute it.
This is the part that breaks the usual mental model. We treat context like memory, where more is safer, and forgetting is the failure mode. For a long-horizon tool-using agent it is closer to the opposite. The failure mode is carrying everything forward and forcing the model to re-derive what is relevant from a pile that grows every step. Pruning is not lossy compression you tolerate to save money. In this benchmark, pruning was the thing that made the agent more correct.
No, and the numbers make the distinction sharp. A bigger window gives you room. It does not tell the model what to do with that room. The full-history run in this benchmark was not failing because it ran out of space. It fit, at 1,480,996 tokens, and still lost to a pruned run roughly a third its size.
It costs you twice, once on the bill and once on the clock, before you even count the accuracy gap. Full history burned 1,480,996 tokens and 14.56 hours of runtime across the benchmark. Prune-plus-summarize did the same work in 553,374 tokens and 5.79 hours, and scored higher doing it. That is roughly a third of the tokens and under half the wall-clock, with better results, not the usual speed-for-quality trade.
Full history vs prune-and-summarize, on the same 50 tasks
dimension
Full history
Prune + summarize
Task completion
71.0%
91.6%
Tokens consumed
1,480,996
553,374
Runtime
14.56 hours
5.79 hours
What you're paying for
Re-reading stale context
Acting on relevant context
If you run agents at any volume, that token line is your margin and that runtime line is your latency. The "keep everything to be safe" default is quietly the most expensive and least accurate option on the board. The result also held up beyond a single model: the authors confirmed the pattern on Claude Sonnet 4.5, so this is not one model's quirk.
“On a 50-task tool-using benchmark, full conversation history scored 71.0% at 1,480,996 tokens and
14.56 hours. Pruning to the last five tool calls plus summarization scored 91.6% at 553,374 tokens
and 5.79 hours. Selective context retention beat full retention on accuracy, cost, and speed at once.”
More context, less accuracy. The full-history agent scored 71% on roughly 1.48M tokens; pruning and summarizing scored 91.6% on about 553K. Source: Lodha et al., arXiv:2606.10209 (2026).
How do you actually manage context for long-horizon agents?#
You make context a thing the system decides on every step, not a thing it accumulates by default. The benchmark's winning configuration is a recipe you can copy:
Prune to recent tool calls. Keep the last handful of tool-call and response pairs in the working context. In the study, pruning to the last five already lifted completion from 71.0% to 79.0% on its own, before any summarization.
Summarize the rest, do not drop it. Replace the older history with a compact summary instead of either keeping it verbatim or deleting it. That step is what took the agent from 79.0% to 91.6%. The history still informs the agent, it just stops drowning it.
Serve one canonical source per query, not the whole pile. When the agent needs a fact, give it the single authoritative answer to read as fresh input, rather than making it scan an entire transcript or document dump to reconstruct it.
That third point is where this stops being a paper and starts being an operating discipline. It is the principle our own tooling is built on: trovex exists to hand an agent one canonical document per query instead of the whole repository, so the model reads a clean answer rather than re-deriving it from everything it has ever seen. We did not build it from a benchmark. We built it because our own agent fleet got slower and less reliable the more we let context pile up, which is the same failure this paper measured under controlled conditions.
How this changes the way you build an agent system#
The takeaway is not "prune your prompts" as a tuning tip. It is that context selection is an architectural decision you own, the same way you own retries and timeouts. An agent that hoards context is making an implicit choice to be slower, costlier, and less accurate, and the default settings make that choice for you unless you intervene.
In practice that means a context policy per agent: what gets kept, what gets summarized, what gets served fresh from a canonical layer, and at what step boundaries. It means measuring task completion against token spend, not assuming a fuller prompt is a safer one. And it means treating a growing conversation history as a liability to manage, not an asset to protect. This is the operating model we build with teams running agents in production, because "give it more context" is the expensive instinct that feels responsible and quietly degrades the system.
If your agents get slower and flakier the longer they run, you do not have a model problem. You have a context policy you never wrote down. That's the work we do with teams.
We map where your agent system hoards context instead of selecting it, what it is costing you in tokens and latency, and the context policy that fixes it, on your stack.
No. On a 50-task tool-using benchmark, keeping the full conversation history scored 71%, while pruning to the last five tool calls and summarizing the rest scored 91.6%. The same configuration used roughly a third of the tokens. More context added noise the model had to re-read every turn, not accuracy.
Does a bigger context window make an agent more accurate?
Not by itself. A bigger window is capacity, not selection. In the 2026 benchmark the full-history run fit inside the window at 1,480,996 tokens and still lost to a pruned run a third its size. What raised accuracy was choosing which context to keep, not having room to keep all of it.
What is context engineering for agents?
Context engineering is deciding what an agent reads at each step instead of feeding it everything. In practice that means pruning stale tool output, keeping recent calls, summarizing the rest, and serving one canonical document per query. The 2026 benchmark shows it as the difference between 71% and 91.6% task completion.
How much can pruning and summarizing context save?
In the benchmark, full history cost 1,480,996 tokens and 14.56 hours. Pruning plus summarization cost 553,374 tokens and 5.79 hours, while scoring higher (91.6% vs 71%). That is roughly a third of the tokens and under half the runtime, with better accuracy, not a tradeoff against it.